Сегодня мы не можем представить жизнь без передачи информации. Но так было не всегда. Компьютеры научились работать с текстом благодаря появлению кодировок, о которых далее пойдет речь.
Что такое кодирование
При этом кодирование происходит по определенным правилам, которые зависят от назначения кода, то есть от того, как и для чего этот код будет использоваться.
Данная последовательность представляется в виде кодовой таблицы, в которой номера строки и столбца определяют код слова.
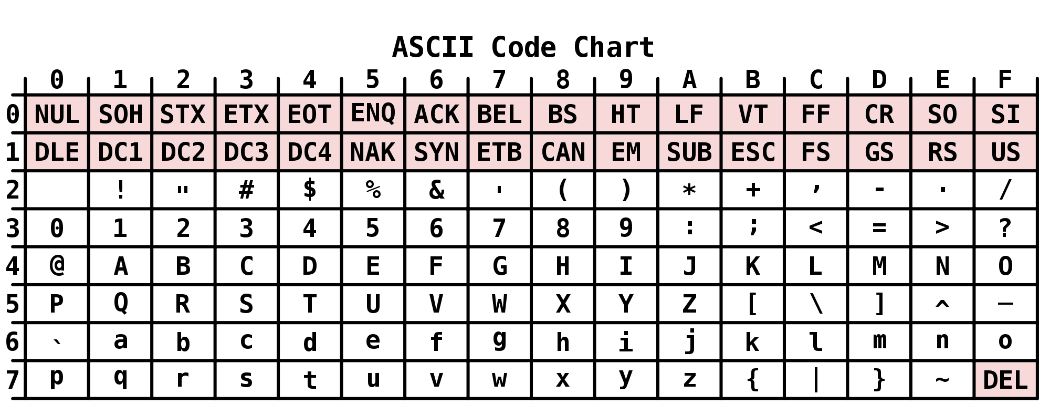
Кодировка ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году.
Кодировка ASCII
При развертывании в двоичную форму коды представляют собой семиразрядные целые двоичные числа в диапазоне от 000 00002 = 0016 = 0 до 111 11112 = 7F16 = 127.
По таблице вы могли заметить, что первые 32 символа обозначают некоторые действия при вводе текста. Этот набор от 00 до 1F называется управляющими символами и не отражаются какими-либо знаками на экране монитора или при печати. Следующие символы, начиная с 2016 имеют графическое отображение.
Пример.
Код 4216 = «В». На экране появляется символ «В».
Таблица ASCII соблюдает алфавитную последовательность прописных, строчных букв и десятичных цифр, что удобно при программной обработке символьной информации, например, для алфавитной сортировки слов.
Кодовые страницы (расширение кода ASCII)
Восьмиразрядная двоичная кодировка позволяет кодировать алфавит из 28 = 256 символов. Таким образом, к первой половине ASCII, присоединяется вторая половина, на которой размещаются нелатинские алфавиты, символы псевдографики и некоторые другие знаки. Эта часть таблицы кодировки называется кодовой страницей (CP – code page).
Кодовая страница СР1251
Пользуется довольно большой популярностью. СР1251 выгодно отличается от других 8-битных кириллических кодировок наличием практически всех символов, использующихся в русской типографике для обычного текста, она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Кодовая страница CP1251 в операционной системе Windows
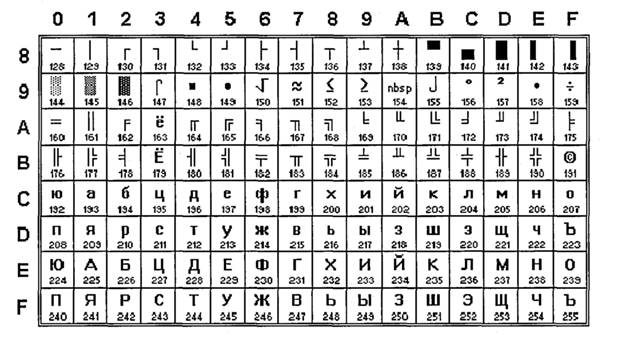
Кодовая страница KOI8
Разработчики КОI8 поместили символы русского алфавита в таблице таким образом, что позиции кириллических символов соответствуют их фонетическим аналогам в английском алфавите в базовой таблице. Это означает, что если в тексте, написанном в КОИ-8, убирать восьмой бит каждого символа (отнять 128), то получается читабельный текст, хотя он и написан латинскими символами.
Пример.
Но из-за такого решения символы кириллицы оказались расположены не в алфавитном порядке.
Существует несколько вариантов кодировки КОI8 для различных кириллических алфавитов. Русский алфавит описывается в кодировке KOI8-R, украинский –– в KOI8-U.
Кодовая страница KOI8
Кодировка Unicode
Еще один стандарт символьной кодировки, где присутствует русский алфавит, – это
Диапазон кодов символов в шестнадцатеричной форме: от 0000 до FFFF, а каждому символу в такой кодировке отводится 2 байта памяти.
В Unicode отпадает потребность в кодовых страницах, так как стандарт включает в себя английский (латиница), русский (кириллица), греческий алфавиты, китайские иероглифы, математические, экономические, технические символы и другое.
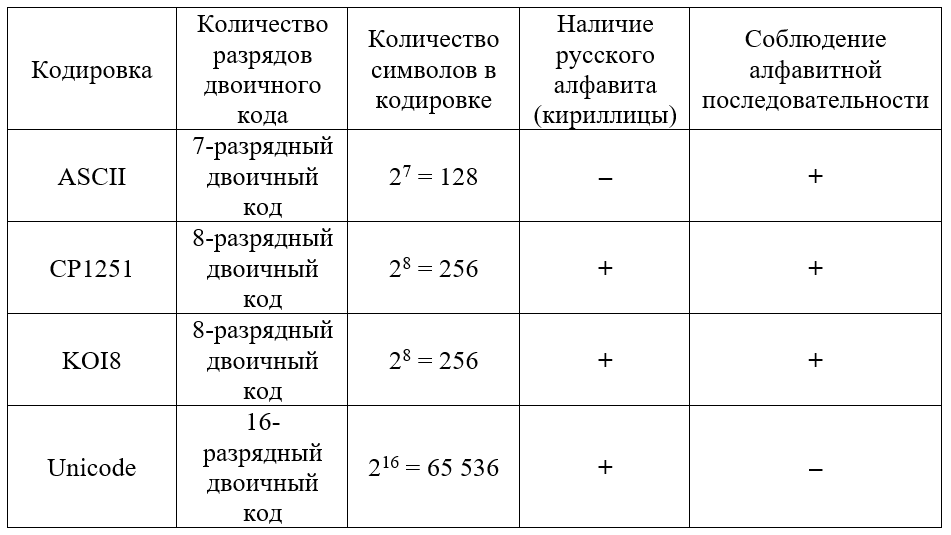
Итог
Таким образом, выбор стандарта зависит от того, как и для чего будет использоваться код. Основные отличия кодировок представлены в таблице:

Содержание